Categorical variables - Uniform encoding
Case Background
A public university seeks to share student academic and enrollment records with campus researchers. These records contain sensitive personal data (socioeconomic status, ethnicity, disability status), previously accessible only to designated teams in controlled environments.
Recent efforts using aggregated data with differential privacy improved access but reduced analytical precision. The Academic Affairs Office is now partnering with the Information Science Department to develop synthetic data solutions that maintain individual-level granularity and analytical accuracy while protecting privacy, aiming to enhance research capabilities and enable future cross-institutional collaboration.
Data Characteristics and Challenges
- High-Cardinality Categorical variables: The diversity of student identity categories, academic departments, and admission programs results in many data fields containing numerous unique values.
Categorical Variables
A Categorical Variable is defined as a variable that can be divided into different categories or groups, where values represent classifications rather than measured values. These values are typically discrete, non-numeric labels such as gender (male, female), blood type (A, B, AB, O), city names, or education levels, and can be either nominal scale (unordered categories, such as colors) or ordinal scale (with natural ordering, such as education levels).
Since most synthetic data models, as well as statistical and machine learning algorithms, can only accept numerical field inputs, encoding is used to process nominal or ordinal scale categorical variables, allowing the data to be understood and processed by models.
Data Table and Business Context
The data structure in this case reflects the university student recruitment and enrollment management process, primarily consisting of one core data table:
Student Basic Information Table:
- Contains diverse information including student personal details (date of birth, zodiac sign, gender), academic background (department code, department name), admission channels (admission type code, admission type), and identity characteristics (disability status, nationality, identity category)
- Each record represents an individual student
- Data fields include a mix of numerical values (such as date of birth) and categorical types (such as zodiac sign, department, admission method)
Notably, this data table contains many high-cardinality categorical variables (such as department codes and names), as well as privacy-sensitive personal information (such as birth dates and identity categories). These characteristics require special attention during data synthesis to protect personal privacy while preserving relationships between data and statistical features, ensuring that synthetic data can support practical needs for educational research and decision analysis.
Demonstration Data
Considering data privacy, the following uses simulated data to demonstrate data structure and business logic. While these data are simulated, they retain the key characteristics and business constraints of the original data:
| birth_year | birth_month | birth_day | zodiac | university_code | university | college_code | college | department_code | department_name | admission_type_code | admission_type | disabled_code | disabled_type | nationality_code | nationality | identity_code | identity | sex |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2005 | 4 | 9 | 牡羊座 | 002 | 國立政治大學 | 700 | 理學院 | 702 | 心理學系 | 01 | 學士班 (指考分發/聯考) | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 女 | |
| 2003 | 1 | 16 | 摩羯座 | 001 | 國立臺灣大學 | 2000 | 理學院 | 2080 | 地理環境資源學系 | 46 | 繁星推薦 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 女 | |
| 2002 | 11 | 7 | 天蠍座 | 001 | 國立臺灣大學 | 1000 | 文學院 | 1070 | 日本語文學系 | 51 | 學士班申請入學 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 男 | |
| 2002 | 12 | 24 | 摩羯座 | 001 | 國立臺灣大學 | 9000 | 電機資訊學院 | 9020 | 資訊工程學系 | 46 | 繁星推薦 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 男 | |
| 2000 | 10 | 7 | 天秤座 | 001 | 國立臺灣大學 | 1000 | 文學院 | 1040 | 哲學系 | 51 | 學士班申請入學 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 女 |
Encoding Categorical Variables
Different encoding methods are suitable for different categorical variable characteristics and contexts. Our team has compiled a comparison of several mainstream encoding methods as follows:
| Characteristic/Evaluation Criteria | Label Encoding | Target Encoding | Uniform Encoding | One-hot Encoding | Feature Hashing | Entity Embedding |
|---|---|---|---|---|---|---|
| Preserves Non-ordinality | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Dimensionality Handling | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| Rare Category Handling | ✅ | ⚠️ | ❌ | ✅ | ✅ | ❌ |
| New Category Handling | ❌ | ❌ | ❌ | ❌ | ✅ | ❌ |
| Captures Latent Semantic Relations | ❌ | ⚠️ | ❌ | ❌ | ❌ | ✅ |
| Data Leakage Risk | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ |
| Computational Efficiency | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ |
| Memory Requirements | ✅ | ✅ | ✅ | ❌ | ✅ | ⚠️ |
| Manual Adjustment Needs | ✅ | ⚠️ | ✅ | ✅ | ⚠️ | ❌ |
| Interpretability | ⚠️ | ⚠️ | ⚠️ | ✅ | ❌ | ❌ |
| High Cardinality Handling | ❌ | ✅ | ⚠️ | ❌ | ✅ | ✅ |
Symbol Legend:
- ✅ Advantage/Supported
- ⚠️ Moderate/Requires trade-off
- ❌ Disadvantage/Not supported
The academic community is still researching more universal and robust encoding strategies. Our team recommends initially using Uniform Encoding for all categorical variables as recommended by SDV 1. When encountering high cardinality categorical variables—fields with many unique values—current mainstream encoding methods all have certain limitations. We recommend complementing this approach with the High-Cardinality attributes - Constraints discussed in the next article.
Uniform Encoding
Uniform Encoding is a categorical variable processing method proposed by datacebo, specifically designed to enhance the performance of generative models 2. Its core concept is mapping discrete categorical values to a continuous [0,1] interval, where the size of each category’s corresponding interval is determined by its frequency in the original data. This method effectively transforms categorical information into continuous values while preserving the statistical characteristics of the category distribution.
In practice, if a categorical variable contains three categories ‘a’, ‘b’, and ‘c’ with occurrence ratios of 1:3:1, the encoding will map ‘a’ to the [0.0, 0.2) interval, ‘b’ to the [0.2, 0.8) interval, and ‘c’ to the [0.8, 1.0] interval, randomly selecting values within each respective interval. During restoration, the original category is determined based on which interval the numerical value falls into. This bidirectional transformation mechanism ensures data integrity throughout the modeling and restoration process.
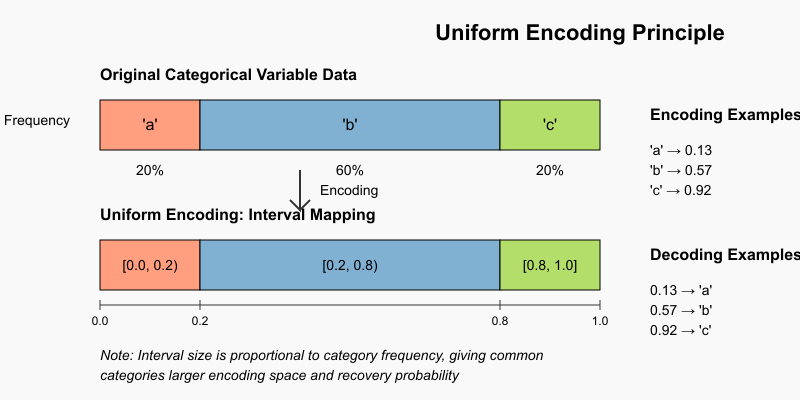
The main advantages of Uniform Encoding lie in simultaneously solving multiple data processing challenges: it transforms discrete distributions into continuous distributions for easier modeling, provides a fixed value range for convenient restoration, and preserves the original distribution information so that common categories have a greater sampling probability. This encoding method is particularly suitable for features with fewer categories and imbalanced category distribution scenarios. It can be flexibly combined with other preprocessing methods and demonstrates excellent performance in generative model applications.
Full Demonstration
Click the button below to run the example in Colab:
![]()
In fact, PETsARD uses Uniform Encoding as the default encoding method for categorical variables. The settings here are only meant to skip outlier processing (‘outlier’) in the default workflow, which would remove too many records in this simulated dataset. You only need to use the default mode with Preprocessor, and it will automatically apply Uniform Encoding to your categorical variables.
Preprocessor:
encoding_uniform:
sequence:
- 'encoder'
encoder:
birth_year: 'encoding_uniform'
birth_month: 'encoding_uniform'
birth_day: 'encoding_uniform'
zodiac: 'encoding_uniform'
deparment_code: 'encoding_uniform'
department_name: 'encoding_uniform'
admission_type_code: 'encoding_uniform'
admission_type: 'encoding_uniform'
disabled_code: 'encoding_uniform'
disabled_type: 'encoding_uniform'
nationality_code: 'encoding_uniform'
nationality: 'encoding_uniform'
identity_code: 'encoding_uniform'
identity: 'encoding_uniform'
sex: 'encoding_uniform'Results as below:
| birth_year | birth_month | birth_day | zodiac | university_code | university | college_code | college | department_code | department_name | admission_type_code | admission_type | disabled_code | disabled_type | nationality_code | nationality | identity_code | identity | sex |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2004 | 6 | 10 | 天蠍座 | 001 | 國立臺灣大學 | 9000 | 電機資訊學院 | 101 | 電機工程學系 | 51 | 學士班申請入學 | 1 | 有身心障礙 | nan | 中華民國 | 12 | 一般生 | 男 |
| 2001 | 12 | 7 | 天蠍座 | 001 | 國立政治大學 | 100 | 資訊學院 | 117 | 中國文學系 | 51 | 繁星推薦 | 1 | 有身心障礙 | nan | 中華民國 | 21 | 原住民 (泰雅族) | 男 |
| 2004 | 2 | 23 | 處女座 | 002 | 國立政治大學 | 2000 | 理學院 | 101 | 大氣科學系 | 51 | 繁星推薦 | 1 | 有身心障礙 | nan | 中華民國 | 4 | 一般生 | 男 |
| 2004 | 7 | 29 | 摩羯座 | 001 | 國立臺灣大學 | 2000 | 理學院 | 474 | 電機工程學系 | 51 | 繁星推薦 | 1 | 有身心障礙 | nan | 中華民國 | 33 | 原住民 (泰雅族) | 男 |
| 2003 | 4 | 19 | 牡羊座 | 002 | 國立政治大學 | 1000 | 電機資訊學院 | 101 | 應用數學系 | 51 | 學士班申請入學 | 1 | 有身心障礙 | nan | 中華民國 | 2 | 一般生 | 女 |
Should Time be Treated as Categorical Variables?
When time is stored as separate year, month, and day fields, treating them as categorical variables is recommended. These elements have finite ranges and specific semantics that align with categorical data characteristics. Time components like months have cyclical properties, and treating them as continuous values can lead to inappropriate interpolation during synthesis, especially with floating-point calculations.
If time is stored as datetime type, treating it as numerical would better preserve periodicity. While merging separate date elements for processing and splitting them afterward is technically possible, PETsARD doesn’t support this. Users needing this functionality should handle time format conversion during preprocessing to achieve better time series modeling.
References
Synthetic Data Vault. (n.d.). UniformEncoder. In RDT Transformers Glossary. Retrieved 2025, from https://docs.sdv.dev/rdt/transformers-glossary/categorical/uniformencoder ↩︎
Patki, N., & Palazzo, R. (2023, August 28). Improving synthetic data up to +40% (without building new ML models). Datacebo. https://datacebo.com/blog/improvement-uniform-encoder/ ↩︎