ML Utility
Machine learning utility evaluation aims to assess the practical value of synthetic data by analyzing its performance across various machine learning tasks. High-quality synthetic data should preserve the predictive patterns of the original data and demonstrate comparable machine learning performance in downstream tasks.
The MLUtility evaluator module in PETsARD currently employs a “Dual-Model Control Group” evaluation design, which rigorously considers future data generalization capabilities under experimental control and ensures the reliability of using synthetic data alone for analysis and development.
However, our team believes that different evaluation designs are suitable for different assessment goals and application scenarios. In particular, the requirement to “reserve a control group in advance” may present practical challenges, and the National Institute of Standards and Technology (NIST) in its de-identification guidelines (NIST SP 800-188) also adopts a simplified “Domain Transfer” experimental design1.
To help users better understand machine learning utility evaluation, whether for data release or data augmentation purposes, we have compiled several major experimental design methods to enable users to select the most appropriate evaluation method for their specific needs.
Available Machine Learning Utility Experimental Designs
The core concept of machine learning utility evaluation is: High-quality synthetic data should maintain a similar conditional distribution P(Y|X) to the original data, enabling models trained on it to achieve comparable generalization performance. As synthetic data is an emerging field, academia has not yet established a comprehensive taxonomy of experimental design methodologies for synthetic data evaluation. The following is our team’s perspective and classification framework based on practical experience and theoretical research.
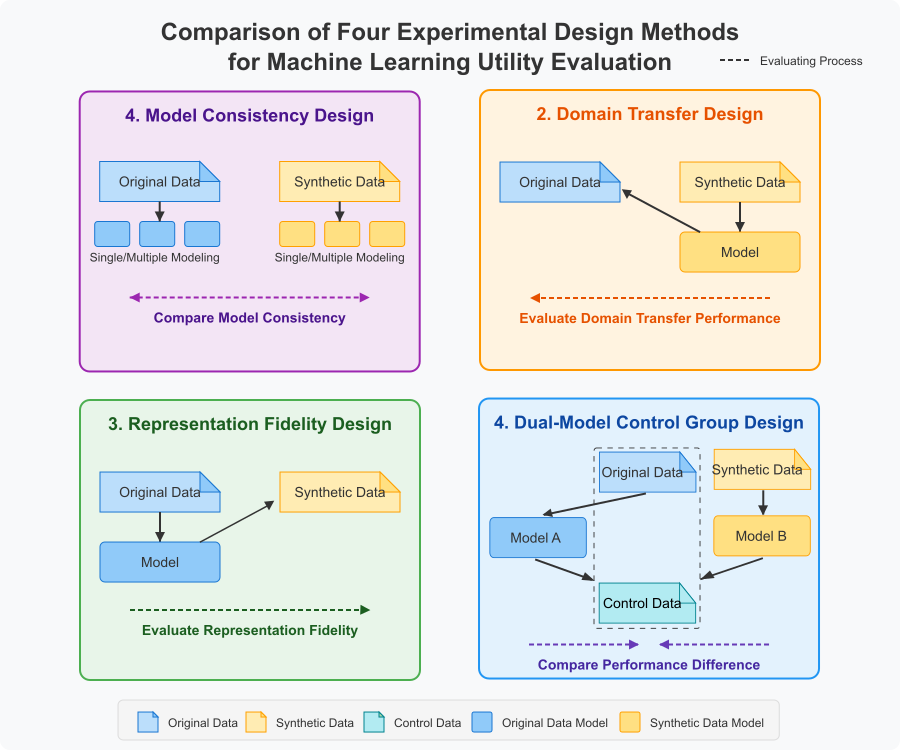
1. Model Consistency Method
Evaluation Process:
- Train multiple models with different configurations (on both original and synthetic data)
- Compare the consistency of model performance rankings on cross-validation sets, such as by comparing rank correlations of model performance
Theoretical Foundation:
- Model Ranking Consistency is based on the ranking in Model Selection
- Related to model ranking consistency and hyperparameter optimization in Automated Machine Learning (AutoML)
- Uses rank correlation coefficients such as Spearman’s Rank Correlation
Applicable Scenarios:
- Evaluating whether synthetic data can help select the same optimal model as original data
- Suitable for model selection and hyperparameter tuning scenarios
- Scenarios focusing on relative performance rather than absolute performance
2. Domain Transfer Method
Evaluation Process:
- Train models on synthetic data
- Test model performance on original data
Theoretical Foundation:
- Domain Transfer is based on Transfer Learning and Domain Adaptation theory
- Similar to evaluating generalization ability from source to target domain in machine learning
- Uses common machine learning metrics, but these metrics represent Transfer Efficiency or Cross-Domain Generalization Error
Applicable Scenarios:
- Evaluating the deployment performance of models trained on synthetic data in real environments
- Focusing on model generalization capabilities from synthetic to real domains
- Suitable for applications planned for deployment in real environments
3. Representation Fidelity Method
Evaluation Process:
- Train models on original data
- Test model performance on synthetic data
Theoretical Foundation:
- Representation Fidelity is based on Distribution Similarity and Representation Learning theory
- Related to Covariate Shift metrics in Distribution Shift theory
- Uses common machine learning metrics, but these metrics represent Representation Fidelity or Distribution Match
Applicable Scenarios:
- Evaluating whether synthetic data captures the distribution and patterns of original data
- Measuring the degree to which the synthesis process preserves the structure of original data
- Suitable for synthetic data quality validation scenarios
4. Dual-Model Control Group Method
Evaluation Process:
- Train a specific model on original data, called Model A
- Train the same model on synthetic data, called Model B
- Test both models using a common control group dataset
- Compare the performance difference between Model A and Model B
Theoretical Foundation:
- Dual-Model Control Group is based on parallel control group design in experimental design theory
- Through the control in the experimental design itself, fairly evaluating the performance delta (Utility Gap) between original and synthetic data
Applicable Scenarios:
- Evaluating whether synthetic data can directly replace original data for model development
- When focusing on the degree of preserved predictive capability
- Suitable for data sharing and model development scenarios
Comparison
| Evaluation Method | Pre-synthesis Control Group | Evaluation Metrics | Theoretical Basis | Applicable Scenarios | PETsARD Feature |
|---|---|---|---|---|---|
| Model Ranking Consistency Method | Flexible | Metric Rank Correlation | Model Selection Theory | Optimal Model Filtering | None |
| Domain Transfer Method | Flexible | General Statistical Metrics | Domain Adaptation Theory | Deployment Generalization Assessment | None |
| Representation Fidelity Method | Flexible | General Statistical Metrics | Distribution Similarity | Structure Preservation Validation | None |
| Dual-Model Control Group Method | Required | Metric Gap | Parallel Control Group Experimental Design | Data Substitution Assessment | Default |
Indicator Aggregation Methods
Setting Acceptance Standards:
Users are recommended to establish clear acceptance standards before evaluation, such as:
- General statistical indicators: Meeting recommended thresholds
- Indicator gaps: Differences within ±10%
- Indicator rank correlations: Correlation coefficients ≥ 0.7
The indicator thresholds provided by our team are general recommendations only, not universal standards with strict academic foundations.
In practice, governments often establish applicable standards based on local regulations in consultation with industry experts.
Given the significant diversity of data across different domains, establishing unified indicator standards is unrealistic. We recommend that users independently or collaboratively develop standards appropriate for their specific application scenarios within their industry.
Task Selection Considerations:
- It’s important to note that different datasets may not be suitable for all downstream tasks. For example, datasets consisting entirely of numerical fields may not be applicable to certain specific tasks.
- Therefore, not all evaluation methods need to cover all task types.
- Based on training objectives and data utilization specificity, our team recommends prioritizing classification tasks.
- If cross-downstream task comprehensive evaluations are required due to domain needs, users can employ arithmetic means of multiple indicators or set weights according to business importance for weighted calculations.
NIST SP 800-188 “De-Identifying Government Data Sets” (Sept. 2023 version), Section 4.4.5. “Synthetic Data with Validation” ↩︎