類別變項 - 均勻編碼
個案背景
某公立大學教務處擁有豐富的學生入學資訊與學業表現紀錄,希望能更廣泛地提供這些資料給校內教育政策與社會經濟研究學者使用。然而,這些資料包含社經背景、族裔、身心障礙等高度敏感個資,過去僅能透過指定研究案方式,由受限研究團隊在封閉環境下使用,容易引發學術資源公平近用的疑慮。
近兩年,該校採取將資料匯總並導入差分隱私技術的作法,讓校內教研團隊可公開申請使用,但此方法一定程度限制了資料分析的精確度,讓團隊難以評估研究成果的泛化能力。基於對現有資料準確性的評估需求,以及未來跨校系合作的長遠展望,該教務處與資訊系所合作,正尋求能兼顧資料準確性與個資保護的解決方案,期望透過合成資料技術,以一筆學生一筆資料的顆粒度開放原始精度的學術使用,同時協助評估隱私保護與資料可用性間的最佳平衡點。
資料特性與挑戰
- 高基數類別變數:因學生身份類別多樣、系所與入學方案也眾多,許多欄位都具有大量獨特值。
類別變項
類別變數(Categorical Variable)的定義是指那些可分為不同類別或群組的變數,其值代表某種分類而非測量數值。這些值通常是離散的、非數值性質的標籤,如性別(男、女)、血型(A、B、AB、O)、城市名稱或教育程度等,可以是名義尺度(無序的類別,如顏色)或順序尺度(具有自然排序,如教育程度)。
由於大多數合成資料模型、乃至統計與機器學習算法都僅能接受數值型欄位輸入,藉由編碼 (encoding) 來處理名目或順序尺度的類別變項,使得資料能被模型理解與運算。
資料表與業務意義
本案例的資料結構反映了大學學生招生與入學管理的業務流程,主要包含一個核心資料表:
學生基本資料表:
- 包含學生個人資訊(出生年月日、星座、性別)、學術背景(系所代碼、系所名稱)、入學管道(入學方式代碼、入學方式)以及身分特徵(身心障礙狀況、國籍、身分別)等多元資訊
- 每筆記錄代表一位獨立的學生個體
- 資料欄位既包含數值型態(如出生年月日)也包含類別型態(如星座、系所、入學方式)的混合資訊
值得注意的是,此資料表中包含許多高基數類別變項(如系所代碼與名稱),以及具有隱私敏感性的個人資訊(如出生日期、身分別等)。這些特性使得資料合成時需特別注意保護個資隱私,同時保留資料間的關聯性與統計特徵,以確保合成資料能夠支持教育研究與決策分析的實際需求。
模擬資料示範
考量資料隱私,以下使用模擬資料展示資料結構與商業邏輯。這些資料雖然是模擬的,但保留了原始資料的關鍵特性與業務限制:
| birth_year | birth_month | birth_day | zodiac | university_code | university | college_code | college | department_code | department_name | admission_type_code | admission_type | disabled_code | disabled_type | nationality_code | nationality | identity_code | identity | sex |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2005 | 4 | 9 | 牡羊座 | 002 | 國立政治大學 | 700 | 理學院 | 702 | 心理學系 | 01 | 學士班 (指考分發/聯考) | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 女 | |
| 2003 | 1 | 16 | 摩羯座 | 001 | 國立臺灣大學 | 2000 | 理學院 | 2080 | 地理環境資源學系 | 46 | 繁星推薦 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 女 | |
| 2002 | 11 | 7 | 天蠍座 | 001 | 國立臺灣大學 | 1000 | 文學院 | 1070 | 日本語文學系 | 51 | 學士班申請入學 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 男 | |
| 2002 | 12 | 24 | 摩羯座 | 001 | 國立臺灣大學 | 9000 | 電機資訊學院 | 9020 | 資訊工程學系 | 46 | 繁星推薦 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 男 | |
| 2000 | 10 | 7 | 天秤座 | 001 | 國立臺灣大學 | 1000 | 文學院 | 1040 | 哲學系 | 51 | 學士班申請入學 | 0 | 無身心障礙 | 中華民國 | 1 | 一般生 | 女 |
類別變項的編碼
不同的編碼方法適用於不同類別變數特性與情境,本團隊整理現在主流的幾種編碼比較如下:
| 特性/評估標準 | 標籤編碼 | 目標編碼 | 均勻編碼 | 獨熱編碼 | 特徵哈希 | 實體嵌入 |
|---|---|---|---|---|---|---|
| 保留無順序性 | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 維度處理能力 | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| 對罕見類別處理 | ✅ | ⚠️ | ❌ | ✅ | ✅ | ❌ |
| 對全新類別處理 | ❌ | ❌ | ❌ | ❌ | ✅ | ❌ |
| 捕捉潛在語意關係 | ❌ | ⚠️ | ❌ | ❌ | ❌ | ✅ |
| 資料洩漏風險 | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ |
| 運算效率 | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ |
| 記憶體需求 | ✅ | ✅ | ✅ | ❌ | ✅ | ⚠️ |
| 人工調整需求 | ✅ | ⚠️ | ✅ | ✅ | ⚠️ | ❌ |
| 可解釋性 | ⚠️ | ⚠️ | ⚠️ | ✅ | ❌ | ❌ |
| 高基數類別處理 | ❌ | ✅ | ⚠️ | ❌ | ✅ | ✅ |
符號說明:
- ✅ 優勢/支持
- ⚠️ 中等/需要權衡
- ❌ 劣勢/不支持
- 標籤編碼 (Label encoding):適用於順序尺度和效能關鍵的記憶體受限環境。無法捕捉類別間關係且容易誤導模型認為類別間存在順序關係。
- 目標編碼 (Target encoding):適用於基數較高、且下游預測任務明確。易導致資料洩漏、過擬合、且對罕見類別的估計不穩定。
- 均勻編碼 (Uniform encoding):適用於需要保持類別頻率分布的場景。對於罕見類別及數據分布變化時較不穩定。
- 獨熱編碼 (One-hot encoding):適用於低基數類別和需要高度可解釋性的場合。高基數時維度爆炸導致運算與記憶體效率低下。
- 特徵哈希 (Feature hashing):適用於增量學習和大規模分散式系統。哈希碰撞會導致資訊丟失且難以解釋、無法逆向映射。
- 實體嵌入 (Entity embedding):適用於需要建模複雜語意關係的場景。需要大量訓練數據和計算資源、且調參困難、解釋性差。
目前學界還在研究更泛用更穩健的編碼策略,本團隊建議類別變項都統一先按照 SDV 推薦的均勻編碼 (Uniform encoder) 使用 1,當遇到高基數、也就是有許多唯一值的類別變項欄位,現行主流的編碼方式都有一定的限制,再搭配下一篇的高基數變項 - 約束條件使用。
均勻編碼
均勻編碼是一種由 datacebo 提出的類別變數處理方法,專為提升生成模型效果而設計 2。其核心理念是將離散的類別值映射到連續的 [0,1] 區間上,且每個類別對應的區間大小由其在原始資料中的出現頻率決定。這種方法能有效地將類別資訊轉換為連續值,同時保留類別分布的統計特性。
在實際操作中,若某類別變數包含出現比例為 1:3:1 的三個類別 ‘a’、‘b’、‘c’,則編碼時會將 ‘a’ 映射到 [0.0, 0.2) 區間、‘b’ 映射到 [0.2, 0.8) 區間、‘c’ 映射到 [0.8, 1.0] 區間,並在各自區間內隨機取值。還原時則根據數值落入的區間來對應回原始類別。這種雙向轉換機制確保了資料在建模與還原過程中的完整性。
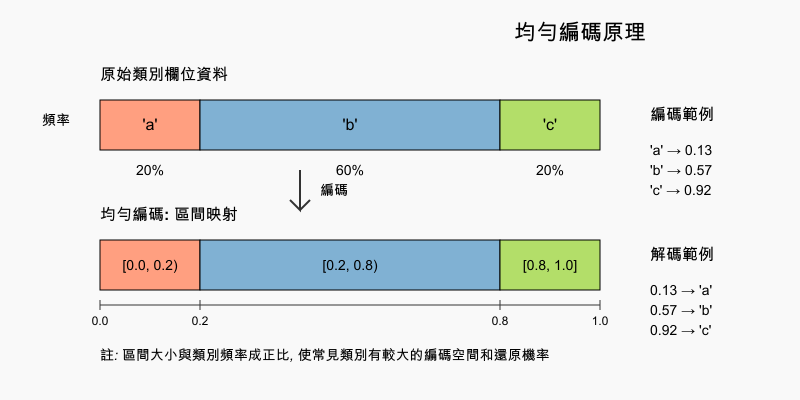
均勻編碼的主要優勢在於同時解決了多個資料處理難題:它將離散分布轉換為連續分布以便於建模,提供固定的值域範圍便於還原,且保留了原始分布資訊使常見類別擁有較大的取樣機率。這種編碼方式特別適用於類別數量較少的特徵以及不平衡的類別分布情境,可與其他前處理方法靈活組合使用,在生成模型應用中展現出色的效能。
完整示範
請點擊下方按鈕在 Colab 中執行範例:
![]()
事實上 PETsARD 預設的類別變項編碼就是均勻編碼,這裡的設定僅是為了在預設流程中略過離群值處理 (‘outlier’,會在本模擬資料中剔除過多的紀錄),您只要對 Preprocessor 使用預設模式,便會自動對你的類別變項均勻編碼處理。
Preprocessor:
encoding_uniform:
sequence:
- 'encoder'
- 'scaler'
encoder:
birth_year: 'encoding_uniform'
birth_month: 'encoding_uniform'
birth_day: 'encoding_uniform'
zodiac: 'encoding_uniform'
deparment_code: 'encoding_uniform'
department_name: 'encoding_uniform'
admission_type_code: 'encoding_uniform'
admission_type: 'encoding_uniform'
disabled_code: 'encoding_uniform'
disabled_type: 'encoding_uniform'
nationality_code: 'encoding_uniform'
nationality: 'encoding_uniform'
identity_code: 'encoding_uniform'
identity: 'encoding_uniform'
sex: 'encoding_uniform'結果如下:
| birth_year | birth_month | birth_day | zodiac | university_code | university | college_code | college | department_code | department_name | admission_type_code | admission_type | disabled_code | disabled_type | nationality_code | nationality | identity_code | identity | sex |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2004 | 6 | 10 | 天蠍座 | 001 | 國立臺灣大學 | 9000 | 電機資訊學院 | 101 | 電機工程學系 | 51 | 學士班申請入學 | 1 | 有身心障礙 | nan | 中華民國 | 12 | 一般生 | 男 |
| 2001 | 12 | 7 | 天蠍座 | 001 | 國立政治大學 | 100 | 資訊學院 | 117 | 中國文學系 | 51 | 繁星推薦 | 1 | 有身心障礙 | nan | 中華民國 | 21 | 原住民 (泰雅族) | 男 |
| 2004 | 2 | 23 | 處女座 | 002 | 國立政治大學 | 2000 | 理學院 | 101 | 大氣科學系 | 51 | 繁星推薦 | 1 | 有身心障礙 | nan | 中華民國 | 4 | 一般生 | 男 |
| 2004 | 7 | 29 | 摩羯座 | 001 | 國立臺灣大學 | 2000 | 理學院 | 474 | 電機工程學系 | 51 | 繁星推薦 | 1 | 有身心障礙 | nan | 中華民國 | 33 | 原住民 (泰雅族) | 男 |
| 2003 | 4 | 19 | 牡羊座 | 002 | 國立政治大學 | 1000 | 電機資訊學院 | 101 | 應用數學系 | 51 | 學士班申請入學 | 1 | 有身心障礙 | nan | 中華民國 | 2 | 一般生 | 女 |
時間是否應該被當作類別變項?
在合成資料生成過程中,時間資料處理策略需根據其儲存形式決定。當時間以年、月、日分開儲存時,建議將其視為類別變項處理。這是因為分離的時間元素各自具有有限的可能值範圍和特定語義,更貼近類別變項的特性。此外,某些時間元素如月份和星期具有循環性質,尤其是某些合成器會在合成中以浮點運算,直接當作連續數值可能導致不適當的插值。
當然若時間以 datetime 型別儲存,則可將其視為數值型變項,會更好的保留週期性。雖然技術上可以將分離的日期元素合併處理、合成後再拆分,但 PETsARD 沒有計劃支援此類操作。若使用者需要此功能,建議在資料前處理階段自行完成時間格式的轉換與合併,以獲得更精確的時間序列模型效果。
參考資料
Synthetic Data Vault. (n.d.). UniformEncoder. In RDT Transformers Glossary. Retrieved 2025, from https://docs.sdv.dev/rdt/transformers-glossary/categorical/uniformencoder ↩︎
Patki, N., & Palazzo, R. (2023, August 28). Improving synthetic data up to +40% (without building new ML models). Datacebo. https://datacebo.com/blog/improvement-uniform-encoder/ ↩︎