機器學習效用
機器學習效用評測旨在評估合成資料的實用價值,通過分析其在各種機器學習任務中的表現來衡量效用。高品質的合成資料應能保留原始資料的預測模式,並在下游任務中展現相近的機器學習效能。
PETsARD 的 MLUtility 評測器模組目前採用「雙模型控制組」評測設計,這種方法嚴格考量了實驗控制下的未來資料泛化能力,確保單獨使用合成資料進行分析與開發的可靠性。
然而,本團隊認為不同的評測設計適用於不同的評估目標和應用場景。特別是「先保留控制組」這一要求在實務操作上可能存在難度,而美國國家標準與技術研究院 (NIST) 在其去識別化指引 (NIST SP 800-188) 中也採用了較為簡化的「領域遷移」實驗設計1。
為幫助使用者更全面理解機器學習效用評測,無論其目的是資料釋出或資料增強,我們整理了幾種主要的實驗設計方法,以便使用者能夠選擇最適合其特定需求的評測方法。
可用的機器學習效用實驗設計
機器學習效用評測的核心思想是:高品質的合成資料應維持與原始資料相似的條件分布 P(Y|X),使得在其上訓練的模型能達到相近的泛化效能。由於合成資料作為一個新興領域,學術界尚未對合成資料評測的實驗設計方法學建立全面性的分類體系。以下是本團隊基於實務經驗與理論研究所提出的觀點與分類架構。
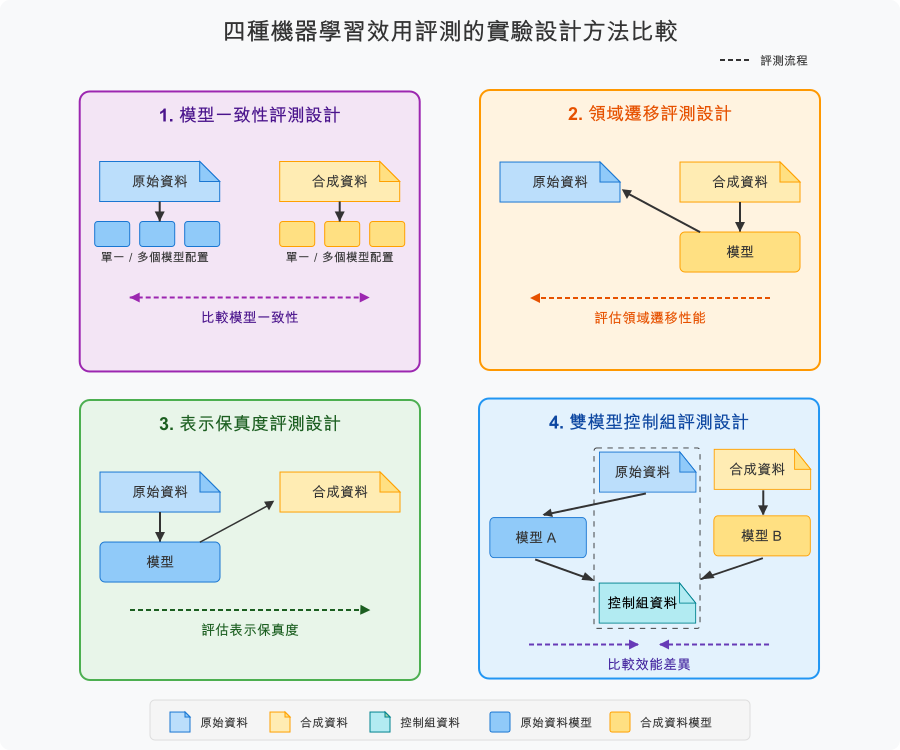
1. 模型一致性評測法
評測流程:
- 訓練多個不同配置的模型(在原始和合成資料上)
- 比較模型在交叉驗證集上的效能一致性,例如比較其模型效能排序相關性
理論基礎:
- 模型排序一致性 (Model Ranking Consistency) 基於模型選擇 (Model Selection) 的排序 (Ranking)
- 與自動化機器學習 (AutoML) 中的模型排序一致性和超參數優化相關
- 使用排序相關係數 (Rank Correlation) 如斯皮爾曼等級相關 (Spearman’s Rank Correlation)
適用場景:
- 評估合成資料是否能幫助選擇與原始資料相同的最佳模型
- 適合模型選擇和超參數調整場景
- 關注相對效能而非絕對效能的場景
2. 領域遷移評測法
評測流程:
- 在合成資料上訓練模型
- 在原始資料上測試模型效能
理論基礎:
- 領域遷移 (Domain Transfer) 基於遷移學習 (Transfer Learning) 和領域自適應理論 (Domain adaptation)
- 類似於機器學習中的源域到目標域 (source to target domain) 泛化能力評估
- 使用常見的機器學習指標,但此時這些指標代表著遷移效率 (Transfer Efficiency) 或域間泛化誤差 (Cross-Domain Generalization Error)
適用場景:
- 評估合成資料訓練的模型在真實環境中的部署效能
- 關注模型從合成域到真實域的泛化能力
- 適合預計部署到真實環境的應用場景
3. 表示保真度評測法
評測流程:
- 在原始資料上訓練模型
- 在合成資料上測試模型效能
理論基礎:
- 表示保真度 (Representation Fidelity) 基於分布相似性 (Distribution Similarity) 和表徵學習理論 (Representation Learning)
- 與資料分布偏移 (Distribution Shift) 理論中的共變量偏移 (Covariate Shift) 指標相關
- 使用常見的機器學習指標,但此時這些指標代表著表徵保真度 (Representation Fidelity) 或分布匹配度 (Distribution Match)
適用場景:
- 評估合成資料是否捕捉了原始資料的分布和模式
- 衡量合成程序保留原始資料結構的程度
- 適合合成資料品質驗證場景
4. 雙模型控制組評測法
評測流程:
- 在原始資料上訓練特定模型,稱為模型 A
- 在合成資料上同樣訓練特定模型,稱為模型 B
- 使用共同的控制組資料測試兩個模型
- 比較模型 A 和模型 B 的效能差異
理論基礎:
- 雙模型控制組 (Dual-Model Control Group) 基於實驗設計理論中的平行控制組設計 (parallel control group design)
- 藉由實驗設計本身控制,公平的評斷原始與合成資料的效能差異 (Performance Delta / Utility Gap)
適用場景:
- 評估合成資料是否能直接取代原始資料進行模型開發
- 當關注的是預測能力的保留程度時
- 適合資料共享和模型開發場景
比較
| 評測方法 | 合成前控制組 | 評測指標 | 理論基礎 | 適用場景 | PETsARD功能 |
|---|---|---|---|---|---|
| 模型排序一致性評測法 | 彈性 | 指標排序相關 | 模型選擇理論 | 最佳模型篩選 | 無 |
| 領域遷移評測法 | 彈性 | 一般統計指標 | 領域自適應理論 | 部署泛化評估 | 無 |
| 表示保真度評測法 | 彈性 | 一般統計指標 | 分布相似性 | 結構保留驗證 | 無 |
| 雙模型控制組評測法 | 必要 | 指標差距 | 平行控制組實驗設計 | 資料替代評估 | 預設 |
機器學習效用評測指標類型
一般統計指標
- 適用於領域遷移評測和表示保真度評測設計
- 直接衡量模型在測試集上的表現能力
- 評估標準依據任務類型有所不同,但一般要求較高的基本表現
| 任務類型 | 建議指標 | 建議模型 | 接受標準 |
|---|---|---|---|
| 分類任務 | ROC AUC | XGBClassifier | 0.8以上可接受 |
| 聚類任務 | 輪廓係數(Silhouette Score) | K-means | 0.5以上可接受 |
| 迴歸任務 | 調整後決定係數(Adjusted R²) | XGBRegressor | 0.7以上可接受 |
指標差距
- 雙模型控制組評測設計法的核心指標
- 測量在原始資料和合成資料上訓練的模型表現差異
- 差距越小表示合成資料越能保留原始資料的預測模式
- 允許正負差異,但絕對值越小越好
| 任務類型 | 建議指標 | 建議模型 | 接受標準 |
|---|---|---|---|
| 分類任務 | ROC AUC分數差異 | 羅吉斯迴歸、SVM、隨機森林分類器、梯度提升分類器 | 差異在 ±10% 以內 |
| 聚類任務 | 輪廓係數差異 | 類別數為4、5、6的K-means | 差異在 ±10% 以內 |
| 迴歸任務 | 決定係數分數差異 | 線性迴歸、隨機森林迴歸、梯度提升迴歸 | 差異在 ±10% 以內 |
指標排序相關
- 適用於模型一致性評測設計
- 評估不同模型配置在原始資料和合成資料上的效能一致性
- 效能一致性定義為模型排序的斯皮爾曼等級相關係數 (Spearman’s ρ),
- 適用於需要選擇最佳模型或超參數的場景
- 關注的是相對效能排序而非絕對效能
| 任務類型 | 建議指標 | 建議模型 | 接受標準 |
|---|---|---|---|
| 分類任務 | ROC AUC 的效能一致性 | 多種模型配置 | 0.7以上表示強相關 |
| 聚類任務 | 輪廓係數的效能一致性 | 不同參數配置的K-means | 0.7以上表示強相關 |
| 迴歸任務 | 調整後決定係數的效能一致性 | 基於樹的多種迴歸模型 | 0.7以上表示強相關 |
指標匯總方式
合格標準制定:
建議使用者在評測前,先行設置明確的合格標準,例如:
- 一般統計指標:達到建議閾值
- 指標差距:差異在 ±10% 以內
- 指標排序相關:相關係數 ≥ 0.7
本團隊提供的指標閾值僅為一般性建議,並非具有嚴格學術基礎的通用標準。
實務上,各國政府通常會依據當地法規,邀集特定產業專家共同訂定適用的標準。
由於不同領域資料具有顯著的特異性,給出統一的指標標準並不現實。建議使用者可自行或與同產業使用者共同規劃訂定符合特定應用場景的合格標準。
任務選擇考量:
- 值得注意的是,不同的資料集可能並不適用於所有下游任務。例如,全為數值型欄位的資料可能難以應用於某些特定任務。
- 因此,並非所有評測方法都需要涵蓋所有任務類型。
- 本團隊基於訓練目標與資料運用的明確性,建議以分類任務為優先考量。
- 若因場域需求,需要進行跨下游任務的綜合評估,可採用多項指標的算術平均值,或按照業務重要性自行設定權重進行加權計算。
NIST SP 800-188《De-Identifying Government Data Sets》2023-09版,章節4.4.5 “Synthetic Data with Validation” ↩︎